贺天行
助理教授
AI模拟,AI游戏,AI安全
I have joined THU-IIIS(清华叉院)as AP in Sep 2024. I plan to work on AI + simulation / gaming / safety. I also work part-time at Shanghai Qi Zhi Institute.
My UW email no longer works (July 1 2024)! Please use my tsinghua email if you want to contact.
长期有效:上海期智研究院的全职科研实习生招募。请gap year的同学关注。
In 2024 I was a postdoc at UW, supervised by Yulia Tsvetkov, who runs the Tsvetshop. A while ago, I was a PhD student at MIT, supervised by Prof. James Glass, who runs the SLS group.
I did my bachelor and master degree at Shanghai Jiao Tong University, and my research there was supervised by Prof. Kai Yu, who runs the SJTU SpeechLab. At SJTU I was in the ACM honored class.
Twitter:
 Research
Research
Interests: AI-related simulation, gaming, or safety. Most of my works during my PhD is focused on neural language generation. Projects: Listed below. Representative papers are highlighted (they are also the projects I lead). * means co-first-author. |
|
Towards Black-Box Membership Inference Attack for Diffusion Models Jingwei Li, Jing Dong, Tianxing He, Jingzhao Zhang Arxiv We propose a surprisingly simple black-box MIA algorithm for diffusion models. |
|
Kabir Ahuja, Vidhisha Balachandran, Madhur Panwar, Tianxing He, Noah A.Smith, Navin Goyal, Yulia Tsvetkov Arxiv We extensively experiment with transformer models trained on multiple synthetic datasets and with different training objectives and show that while other objectives e.g., sequence-to-sequence modeling, prefix language modeling, often failed to lead to hierarchical generalization, models trained with the language modeling objective consistently learned to generalize hierarchically. |
|
MiniAgents: A Visualization Interface for Simulacra Tianxing He Demo project. Currently only Mac is supported. I'm using the Unity game engine to build a visualization interface for simulacra. It's now functional and you are welcome to try it. It's still a work-in-progress. |
|
Stumbling Blocks: Stress Testing the Robustness of Machine-Generated Text Detectors Under Attacks Yichen Wang, Shangbin Feng, Abe Bohan Hou, Xiao Pu, Chao Shen, Xiaoming Liu, Yulia Tsvetkov, Tianxing He ACL 2024 We comprehensively study the robustness of popular machine-generated text detectors under attacks from diverse categories: editing, paraphrasing, prompting, and co-generating. |
|
On the Blind Spots of Model-Based Evaluation Metrics for Text Generation Tianxing He*, Jingyu Zhang*, Tianle Wang, Sachin Kumar, Kyunghyun Cho, James Glass, Yulia Tsvetkov ACL 2023, selfcontained-oral-slide In this work, we explore a useful but often neglected methodology for robustness analysis of text generation evaluation metrics: stress tests with synthetic data. Basically, we design and synthesize a wide range of potential errors and check whether they result in a commensurate drop in the metric scores. Our experiments reveal interesting insensitivities, biases, or even loopholes in existing metrics. Further, we investigate the reasons behind these blind spots and suggest practical workarounds for a more reliable evaluation of text generation. |
|
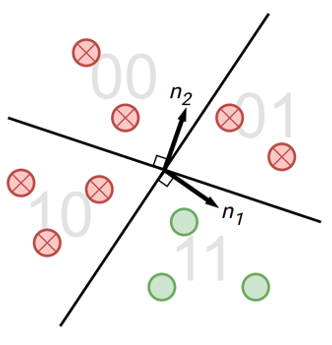
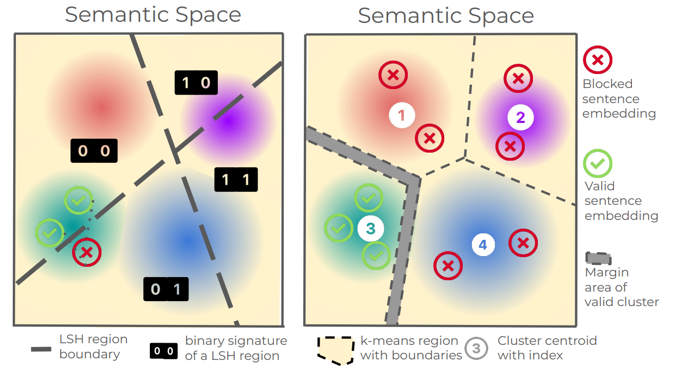
SemStamp: A Semantic Watermark with Paraphrastic Robustness for Text Generation Abe Bohan Hou*, Jingyu Zhang*, Tianxing He*, Yichen Wang, Yung-Sung Chuang, Hongwei Wang, Lingfeng Shen, Benjamin Van Durme, Daniel Khashabi, Yulia Tsvetkov NAACL 2024 Existing watermarking algorithms are vulnerable to paraphrase attacks because of their token-level design. To address this issue, we propose SemStamp, a robust sentence-level semantic watermarking algorithm based on locality-sensitive hashing (LSH), which partitions the semantic space of sentences. |
|
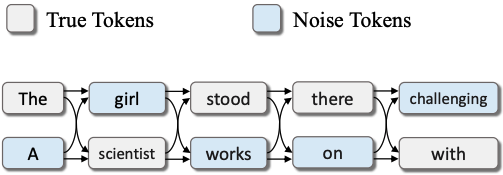
Mengke Zhang*, Tianxing He*, Tianle Wang, Lu Mi, Fatemehsadat Mireshghallah, Binyi Chen, Hao Wang, Yulia Tsvetkov NAACL 2024 Findings In the current user-server interaction paradigm for prompted generation, there is zero option for users who want to keep the generated text to themselves. We propose LatticeGen, a cooperative framework in which the server still handles most of the computation while the user controls the sampling operation. In the end, the server does not know what exactly is generated. The key idea is that the true generated sequence is mixed with noise tokens by the user and hidden in a noised lattice. |
|
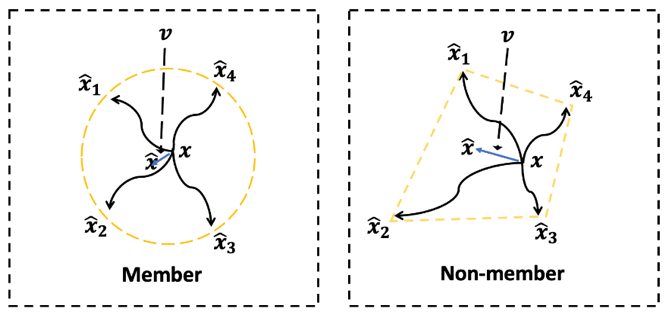
k-SemStamp: A Clustering-Based Semantic Watermark for Detection of Machine-Generated Text Abe Bohan Hou, Jingyu Zhang, Yichen Wang, Daniel Khashabi, Tianxing He ACL-Findings 2024 We propose k-SemStamp, a simple yet effective enhancement of SemStamp, utilizing k-means clustering as an alternative of LSH to partition the embedding space with awareness of inherent semantic structure. |
|
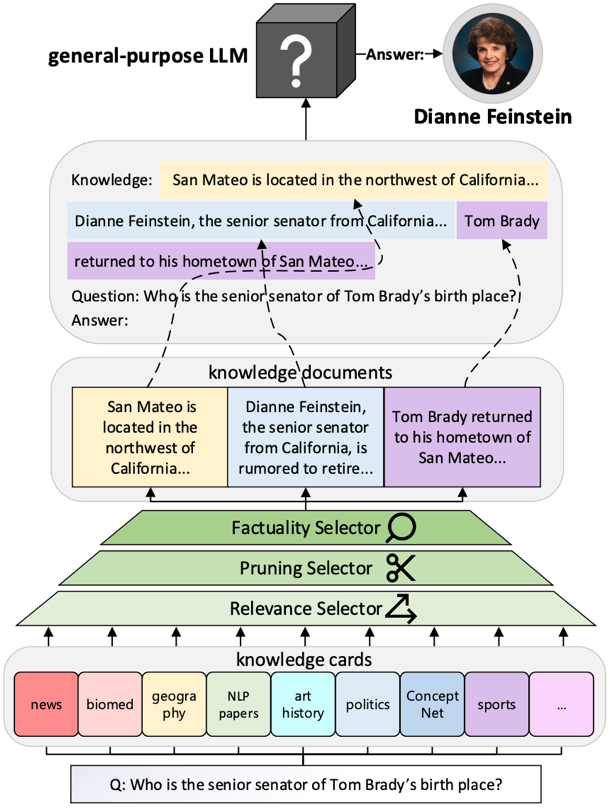
Knowledge Card: Filling LLMs' Knowledge Gaps with Plug-in Specialized Language Models Shangbin Feng, Weijia Shi, Yuyang Bai, Vidhisha Balachandran, Tianxing He, Yulia Tsvetkov ICLR 2024 Reviewer Scores: 8/8/8 We propose Knowledge Card, a community-driven initiative to empower black-box LLMs with modular and collaborative knowledge. By incorporating the outputs of independently trained, small, and specialized LMs, we make LLMs better knowledge models by empowering them with temporal knowledge update, multi-domain knowledge synthesis, and continued improvement through collective efforts. |
|
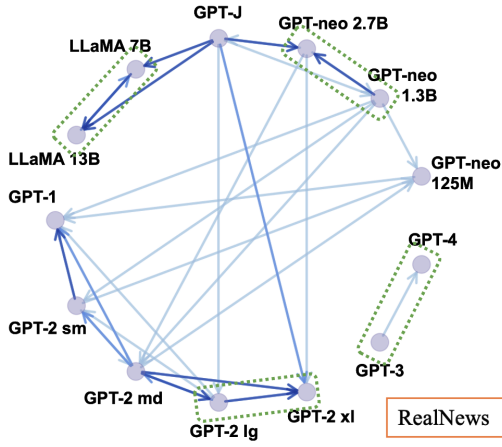
On the Zero-Shot Generalization of Machine-Generated Text Detectors Xiao Pu, Jingyu Zhang, Xiaochuang Han, Yulia Tsvetkov, Tianxing He EMNLP-Findings 2023 How will the detectors of machine-generated text perform on outputs of a new generator, that the detectors were not trained on? We begin by collecting generation data from a wide range of LLMs, and train neural detectors on data from each generator and test its performance on held-out generators. While none of the detectors can generalize to all generators, we observe a consistent and interesting pattern that the detectors trained on data from a medium-size LLM can zero-shot generalize to the larger version. |
|
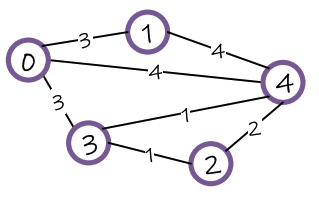
Can Language Models Solve Graph Problems in Natural Language? Heng Wang*, Shangbin Feng*, Tianxing He, Zhaoxuan Tan, Xiaochuang Han, Yulia Tsvetkov NeurIPS 2023 Are language models graph reasoners? We propose the NLGraph benchmark, a test bed for graph-based reasoning designed for language models in natural language. We find that LLMs are preliminary graph thinkers while the most advanced graph reasoning tasks remain an open research question. |
|
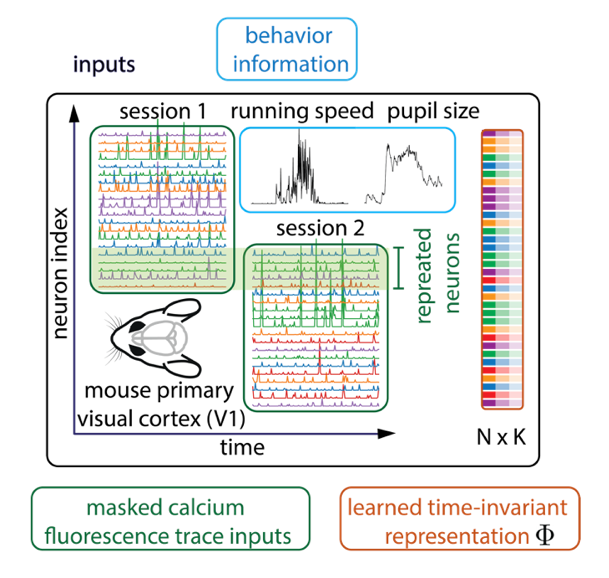
Learning Time-Invariant Representations for Individual Neurons from Population Dynamics Lu Mi*, Trung Le*, Tianxing He, Eli Shlizerman, Uygar Sümbül NeurIPS 2023 We use implicit dynamical models to learn time-invariant representation for individual neurons from population dynamics and enable mapping functional activity to cell types. |
|
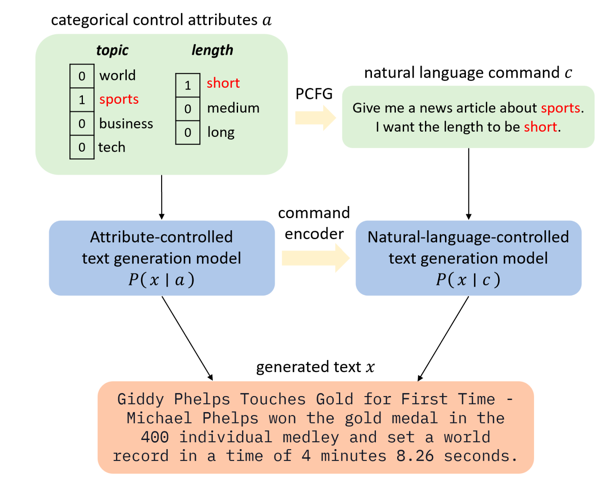
PCFG-based Natural Language Interface Improves Generalization for Controlled Text Generation Jingyu Zhang, James Glass, Tianxing He The 2022 Efficient Natural Language and Speech Processing Workshop (NeurIPS ENLSP 2022) The Best Paper Award at the Workshop The 12th Joint Conference on Lexical and Computational Semantics (StarSEM 2023) We propose a natural language (NL) interface for controlled text generation, where we craft a PCFG to embed the control attributes into natural language commands, and propose variants of existing CTG models that take commands as input. |
|
Controlling the Focus of Pretrained Language Generation Models Jiabao Ji, Yoon Kim, James Glass, Tianxing He ACL-Findings 2022 Different focus in the context leads to different generation! We develop the "focus vector" method to control the focus of a pretrained language model. |
|
Tianxing He, Jingzhao Zhang, Zhiming Zhou, James Glass EMNLP 2021 By feeding the LM with different types of prefixes, we could assess how serious exposure bias is. Surprisingly, our experiments reveal that LM has the self-recovery ability, which we hypothesize to be countering the harmful effects from exposure bias. |
|
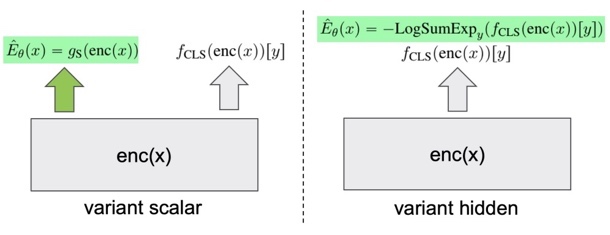
Joint Energy-based Model Training for Better Calibrated Natural Language Understanding Models Tianxing He, Bryan McCann, Caiming Xiong, Ehsan Hosseini-Asl EACL 2021 We explore joint energy-based model (EBM) training during the finetuning of pretrained text encoders (e.g., Roberta) for natural language understanding (NLU) tasks. Our experiments show that EBM training can help the model reach a better calibration that is competitive to strong baselines, with little or no loss in accuracy. |
|
An Empirical Study on Few-shot Knowledge Probing for Pretrained Language Models Tianxing He, Kyunghyun Cho, James Glass On Arxiv We compare a variety of approaches under a few-shot knowledge probing setting, where only a small number (e.g., 10 or 20) of example triples are available. In addition, we create a new dataset named TREx-2p, which contains 2-hop relations. |
|
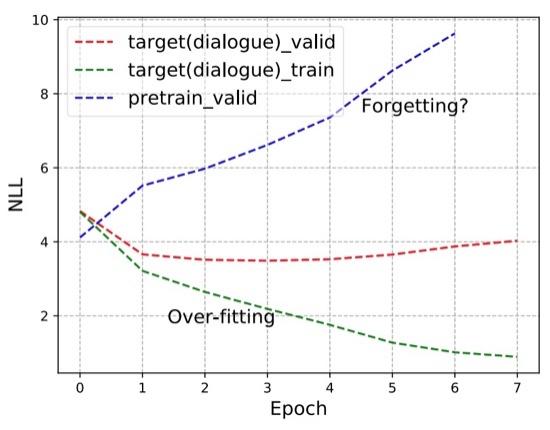
Analyzing the Forgetting Problem in the Pretrain-Finetuning of Dialogue Response Models Tianxing He, Jun Liu, Kyunghyun Cho, Myle Ott, Bing Liu, James Glass, Fuchun Peng EACL 2021 After finetuning of pretrained NLG models, does the model forget some precious skills learned pretraining? We demonstrate the forgetting phenomenon through a set of detailed behavior analysis from the perspectives of knowledge transfer, context sensitivity, and function space projection. |
|
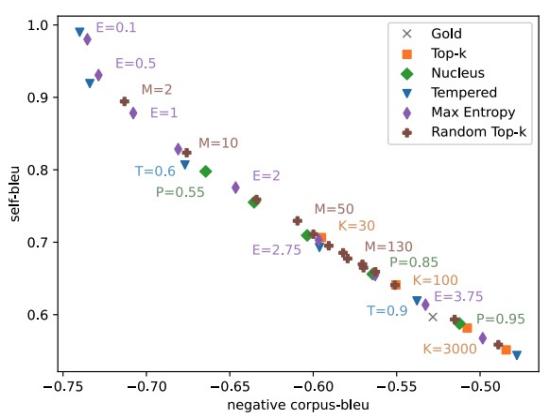
A Systematic Characterization of Sampling Algorithms for Open-ended Language Generation Moin Nadeem*, Tianxing He* (equal contribution), Kyunghyun Cho, James Glass AACL 2020 We identify a few interesting properties that are shared among existing sampling algorithms for NLG. We design experiments to check whether these properties are crucial for the good performance. |
|
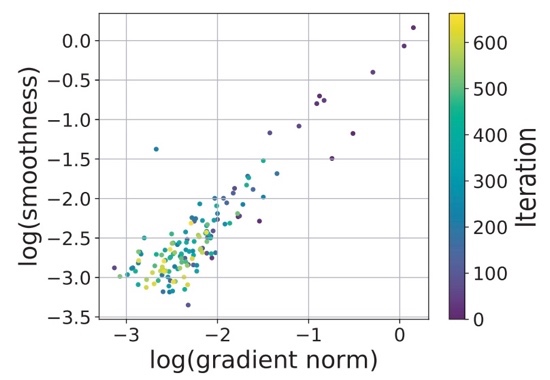
Why Gradient Clipping Accelerates Training: A Theoretical Justification for Adaptivity Jingzhao Zhang, Tianxing He, Suvrit Sra, Ali Jadbabaie ICLR 2020 Reviewer Scores: 8/8/8 We provide a theoretical explanation for the effectiveness of gradient clipping in training deep neural networks. The key ingredient is a new smoothness condition derived from practical neural network training examples. |
|
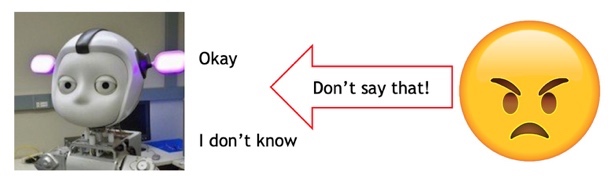
Negative Training for Neural Dialogue Response Generation Tianxing He, James Glass ACL 2020 Can we "correct" some detected bad behaviors of a NLG model? We use negative examples to feed negative training signals to the model. |
|
AutoKG: Constructing Virtual Knowledge Graphs from Unstructured Documents for Question Answering Seunghak Yu, Tianxing He, James Glass Preprint We propose a novel framework to automatically construct a KG from unstructured documents that does not require external alignment. |
|
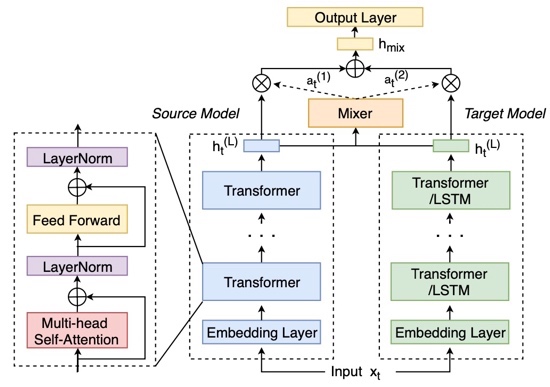
An Empirical Study of Transformer-based Neural Language Model Adaptation Ke Li, Zhe Liu, Tianxing He, Hongzhao Huang, Fuchun Peng, Daniel Povey, Sanjeev Khudanpur ICASSP 2020 We propose a mixer of dynamically weighted LMs that are separately trained on source and target domains, aiming to improve simple linear interpolation with dynamic weighting. |
|
Detecting Egregious Responses in Neural Sequence-to-sequence Models Tianxing He, James Glass ICLR 2019 Can we trick dialogue response models to emit dirty words? |
|
On Training Bi-directional Neural Network Language Model with Noise Contrastive Estimation Tianxing He, Yu Zhang, Jasha Droppo, Kai Yu ISCSLP 2016 We attempt to train a bi-directional RNNLM via noise contrastive estimation. |
|
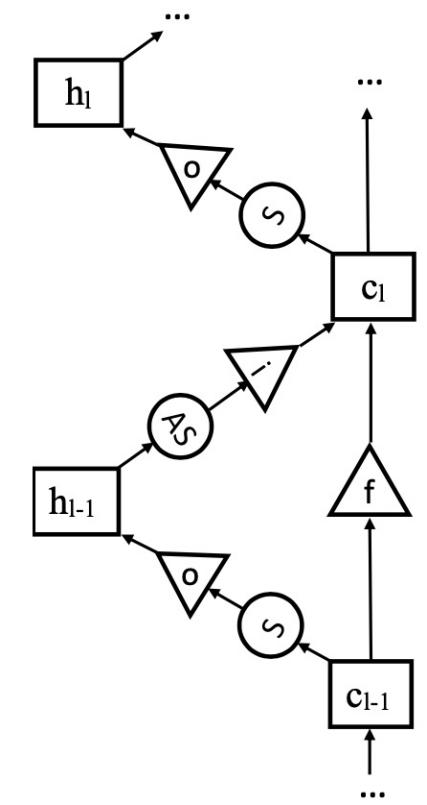
Exploiting LSTM Structure in Deep Neural Networks for Speech Recognition Tianxing He, Jasha Droppo ICASSP 2016 We design a LSTM structure in the depth dimension, instead of its original use in time-step dimension. |
|
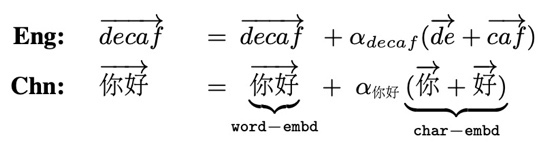
Recurrent Neural Network Language Model with Structured Word Embeddings for Speech Recognition Tianxing He, Xu Xiang, Yanmin Qian, Kai Yu ICASSP 2015 We restructure word embeddings in a RNNLM to take advantage of its sub-units. |
|
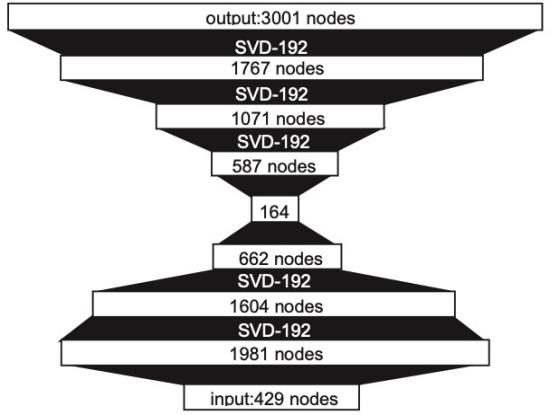
Reshaping Deep Neural Network for Fast Decoding by Node-Pruning Tianxing He, Yuchen Fan, Yanmin Qian, Tian Tan, Kai Yu ICASSP 2014 We prune neurons of a DNN for faster inference. |